When I talk about risk as it relates to web applications, people usually assume I’m talking about hardening applications from hackers, spammers and other ne’er-do-wells. While malicious attacks are absolutely a non-trivial part of risk management, there’s a lot more to it that’s just as important.
What is Risk and Risk Management?
That seems like a painfully obvious question, but at its most basic, risk is anything that could put the success of your project in jeopardy. Risk management is the identification, assessment, and prioritization of risks.
In the context of your web application, attacks from malicious parties (hackers, etc) are certainly one risk, but there are many more that frequently don’t get factored in, which results in disaster when the worst case scenario hits.
If Not Hackers, Then What?
Risk can be anything at all that could impact your application in a way you weren’t expecting. Unexpected popularity (being “slashdotted”, in the language of the old ones) that causes your server to catch fire is a risk. The joke gets made often that “too much traffic is a great problem to have”, but that’s complete bullshit. Whether your server becomes unavailable due to hardware failure, coding errors or the inability to scale, the end result is that you’re down, and the people trying to access your application may never return.
Sometimes the actualization of the risk won’t result in downtime, but could still be seriously damaging to the success of the project.
- A coding failure in a project that results in contest entries not being recorded correctly could result in lawsuits.
- A critical third-party API being unavailable could result in core feature of your application (login, etc) not functioning, which could result in lost customers or bad press.
- A failure in your caching layer could result in massive strain put on your database, which could cause latency or downtime.
- A brittle deployment process could result in the inability to deploy code, or deployments being pushed out that are incomplete or broken.
- An overly complex application or system architecture could mean that when something goes wrong, it’s incredibly difficult to diagnose.
- An obscure or niche choice in tech stack could mean that you’ll have difficulty in finding people to develop this project over time.
- Yes, okay fine, hackers too.
Start Every Project Risk-First
Before any code gets written, as soon as you have an idea of what the requirements will be, you should begin thinking about and documenting potential risks. This should start at the beginning of the project, and the documentation should be added to and reviewed often, all the way through to the project’s completion.
Getting your teams on-board, and getting everyone to start thinking about risk from the beginning is critical to the success of the project. If your developers and systems architects are only thinking about risk after the system has been built, three days before launch, you won’t be in a position to make any changes. Risk should guide you through the entire process, helping you make the most informed, thought-out decisions you can.
Making this part of your process from planning to production is also extremely helpful in mitigating stigmas around risk. Being informed about a project’s risk is good, and positive and healthy for a company, but the risk management folks who aren’t just checking boxes on their compliance forms and who actually give a damn about the success of the project frequently suffer from a reputation of being negative or stifling. Getting all the players on-board from the start gets everyone invested, makes everyone a stakeholder, and means more brains are thinking about potential risk in ways you yourself might overlook.
Embrace Failure to Assess Risk: A Framework
Making peace with the fact that things will sometimes fail is really important. In fact, you should probably get comfortable with the notion that all things will eventually fail. Trust me, you’ll sleep better at night.
How do you determine the level of risk associated with a component? I’ve boiled it down to the following questions. Ask yourself:
- How badly screwed will we be if this component fails?
- What other components will this affect if it fails?
- How likely is it that it will fail?
- What are the ways it could fail?
- What can we do in advance to prevent failure?
- How can we consistently test that this component is healthy?
- How will we know if this failed?
- How can we structure this component to be monitor-able through an external system? (A status JSON/XML script generated, HTTP status codes, etc – anything you can attach a status monitor to.)
- How can we structure this component to fail more gracefully? (Firing an alert and redirecting instead of 500 error, for example)
Managing Risk Doesn’t Mean NOT Innovating and NOT Taking Chances
The point of assessing risk is not to create an outline of hard, fast limitations. You assess risk so that you can make intelligent decisions based on business need and project risk tolerance. Once you have identified risks associated with a particular project, you can start to break down whether or not the risk is avoidable, and whether it’s worth whatever business or technical need created the requirement. Calculated risks are part of good business all the time – but you’ll be in a better position to make those kinds of smart decisions when you can intelligently weigh the pros and cons.
Acceptable risk for your company won’t be the same as acceptable risk for someone else’s. In fact, acceptable risk may vary from client to client or project to project within the same company – even within the project itself. Certain parts of a project may have very high risk tolerance, and other parts may need to be locked down to be rock solid. There is no blanket “right” amount of risk, and there is no such thing as “zero risk”.
Accept That You Can’t Anticipate Every Risk
The very nature of risk means that sometimes, things are going to pop up and bite you in the ass. Something you didn’t think about, something that wasn’t a risk before but for one reason or another is now, something that your team’s previous experience with this technology had never unearthed.
Transparency Around Risk: Creating a Risk Matrix
That’s right – risk matrices aren’t just for compliance weenies anymore. Get in the habit of starting a risk matrix with every project. I usually try to break down every application to its core functional components and enter those into the risk matrix. I also include a worksheet for third-party dependencies. This is important stuff if you’re using any APIs or services where the success of your application relies on an outside organization.
But don’t panic. This matrix doesn’t have to be overly formal or complicated. Here’s an excerpt from the third-party dependence sheet of the risk matrix for a voting application my team worked on.
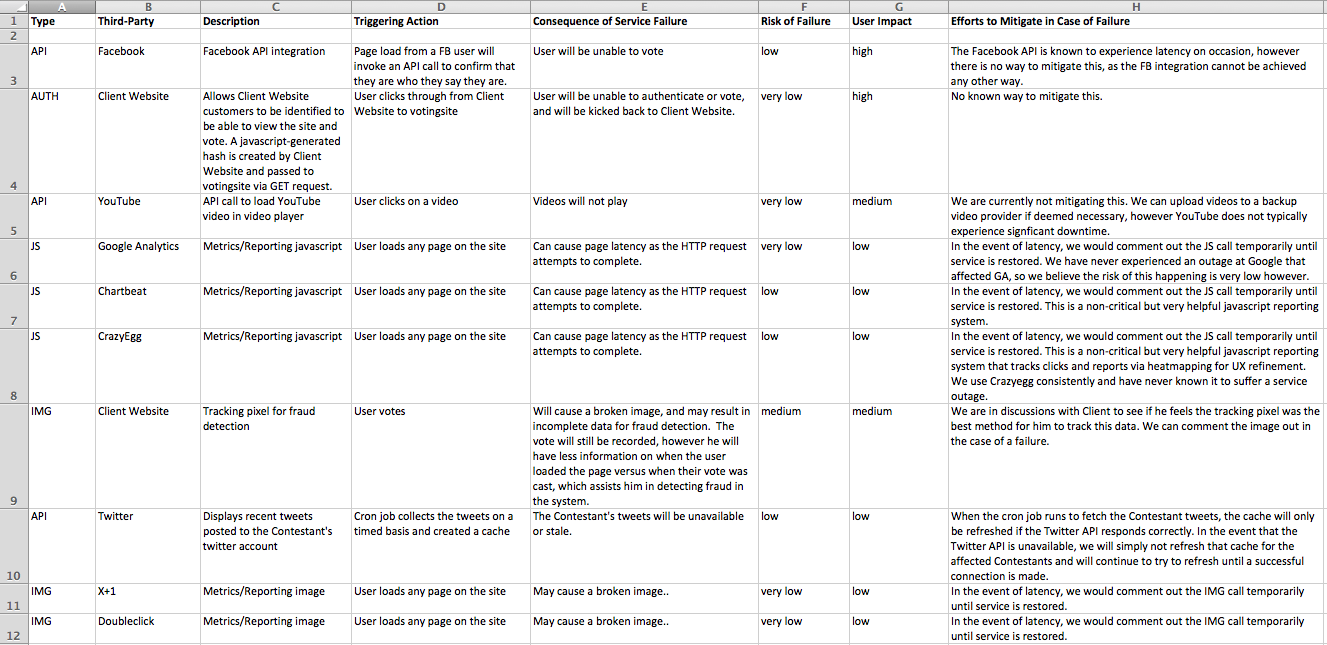
I highly recommend getting management and client sign-off on the risk matrix, at the very least, the third-party sheet. This manages everyone’s expectations well, and shows management and the client that you’ve weighed all of these scenarios and you have a plan for when and if any of them fail.
Each sheet in the matrix has the following information:
- Type
- Third-Party
- Dataflow disagram ID
- Description
- Triggering Action
- Consequence of Service Failure
- Risk of Failure
- User Impact
- Method used for monitoring this risk
- Efforts to Mitigate in Case of Failure
As you can see in my example, there will be many times where the impact of a failure is very high, but the probability is low, which is what helps determine what is acceptable risk. Conversely, the impact may only be low or medium on a component, but if the probability of failure is very high, it may not be worth the user complaints and bad PR.
Always make sure to fill in the “Efforts to Mitigate” column! This is the rough outline of your game plan for when something goes wrong. Don’t wait until the shit hits the fan to try to figure out what you’re going to do. Figure it out and document it early, and you’ll be able to handle these things in stride – with the added bonus that your client and product managers already know what you’re going to do, so they don’t need to interrupt you every 3 seconds while you’re trying to fix things. You could take this further and also include the amount of time the mitigation should take, and so on.
Be sure to include your data flow diagram in this matrix so the information can be kept together easily. Each risk point should be tied back to the element/process number labeled in your data flow diagram.
Don’t feel obligated to stick to just the sheets and fields I’ve created for you in the template. You’re welcome to use any template or format you’d like, as long as you’re keeping track of that information somewhere that’s easy to find and frequently updated. For example, you may want to include software release numbers if specific risks are only a factor with certain releases.
General Advice
While your own systems will have their own requirements, I have some general advice that you should keep in mind:
- Log everything, and review those logs. Use automation to notify you if something doesn’t look right, especially if it pertains to critical functionality. Use a central log server to combine multiple logs so you can start to figure out what’s “normal” for your app and what isn’t.
- Monitor ALL THE THINGS. Every critical piece of functionality should have monitors attached to it.
- Trust your gut. If something doesn’t look right, it probably isn’t.
- Keep your systems as simple as possible. Fewer moving parts is almost always better.
- Don’t abstract code if you don’t have to. Premature optimization is the devil. Build light and refactor as needed.
- Get to know your user’s behavior. Use things like Google Analytics and heatmapping to understand what users do on your site. Be suspicious if it changes for no apparent reason.
This Doesn’t Have to Be Boring
Maybe I’m just lame (no, seriously – it’s quite possible), but I find risk assessment incredibly interesting. I don’t give a crap about checking boxes, but I do give a crap about making awesome apps that are stable and resilient. Figuring out where you can tolerate some risk in exchange for some really badass functionality, and really locking down the foundation stuff that needs to be rock solid is interesting and fun for me. I imagine it like building a beautiful building or amazing sculpture. The gorgeous parts all matter, but they need a solid foundation to rest on, or the whole thing turns into a pile of rubble during the slightest breeze. In the same way that working without any limitations can be exciting, finding creative solutions to limitations can be incredibly rewarding.
Final Note
I gave an ignite talk about this at Foo Camp 2013. My slides are below: